
Originally published on Medium.
2021 marked a big milestone for the Doctolib engineering teams. Our 8-year-old codebase and products finally switched from French to English as a default language/locale.
As Doctolib is not present in any English speaking country, we don't have region-specific locales such as en-GB or en-US, nor do we have multiple French, German or Italian locales. We therefore in the rest of this article use the terms locale and language interchangeably. Localization (formatting of dates, currency, the change of language) and translation in Ruby on Rails are the same process. Only in the front end does localization require extra setting of some packages like Moment.js or Day.js.
It was not an easy move. But we did it for multiple reasons:
- Our products are used by health practitioners and patients in France, Germany and Italy. Whenever a translation would go missing or not be translated in time, defaulting to French on the production website was not making much sense.
- While 3 years ago, almost all of our developers were French (or at least French-speaking), this is not true anymore. We have people coming from more than 40 countries and our tech centers are established in three different European countries. Writing tests in French by default was slowing everybody down. Using the development environment in English was difficult, and not an option known to many developers. In reality it should have been the default option.
- We wanted to make our translation process homogeneous for all countries. In doing so, we addressed problems only the German and Italian teams had been experiencing in the past, such as the delay between merging a pull request and having the translations available in production, or the fact that tests would occasionally fail because of new or changed translations. Specifically, tests testing features only available outside of France but asserting texts in French. When the German or Italian translations would eventually make it to the codebase, those tests would break. We therefore decided all tests now had to be written in English, unless testing a feature only available in one country.
With the whys out of the way, let's now see tips and tricks we've learned — sometimes the hard way.
Tools are your friends, leverage them
Dependencies-wise, we use the default Rails gem to localize our app on the back end, and we use i18n-js on the front end.
In most applications, localization is done through YAML files. For instance, a en.yml file might look like this:
en:
welcome: Welcome to my website
menu_options:
login: Log in
logout: Log out
users_connected:
zero: No users connected
one: One user connected
other: "%{count} users connected"
We refer to full-path YAML keys as "i18n keys". For instance, en.menu_options.login is a full-path YAML key, although the first key in the hierarchy (en as in "English", the language) is generally omitted when talking about i18n keys. We refer to the values as "translations". Here, we have an English translation for each key.
We use Phrase to manage our translations. In Phrase, translations are identified by "i18n key + locale", and alongside their translation string also have two different attributes:
- translated:
trueorfalse. Indicates whether a given key has been translated in a specific locale. Iffalse, it means the translation is an empty string. - verified:
trueorfalse. Indicates whether the existing translation for this couple key+locale was marked as verified or not. It other words, it tells you whether a human approved this translation in Phrase or not.
Phrase can be used through their editor on the website, through their CLI, or through their API.
At Doctolib, every commit to the master branch leads to our file en.yml being uploaded to Phrase. This way, we keep our English translations and our keys in sync with Phrase at all times.
We've set Phrase up so that any new i18n key pushed to Phrase automatically creates the French, German and Italian translations based on the uploaded English translation. This is what they call Machine Translation. It's like Google Translate, but automated. It saves us a lot of time. Then, our UX writers only have to review the translations, correct them if necessary, and mark them as verified.
Phrase is a great tool with many options, that can be configured either in the website or in .phraseapp.yml. After trying different settings for a while, here is what we found to work best for us:
phraseapp:
access_token: # ...
project_id: # ...
file_format: yml
push:
sources:
- file: ./config/locales/en.yml
params:
locale_id: en
file_format: yml
skip_upload_tags: true
update_translations: true
skip_unverification: true
pull:
targets:
- file: ./config/locales/fr.yml
params:
locale_id: fr
include_empty_translations: true
exclude_empty_zero_forms: true
include_unverified_translations: false
# Here, same configuration for de.yml and it.yml
include_unverified_translations: false makes sure only human-verified translations are downloaded when we run phrase_cli pull . This is critical as we don't want machine translated translations to make it to production without any human review, as the translation has oftentimes to be context dependent.
skip_unverification: true makes sure than any edits to an English translation does not unverify (i.e. mark as "not verified") the corresponding FR/DE/IT translations. This may sound counter-intuitive as it means that updates to English translations are not reflected in the other languages as long as no one updates the translations. But it actually allow us to keep our current translations in production. Because of the above-mentioned setting (include_unverified_translations: false) , if we were to mark our translations as unverified, they would actually be removed when we next run phrase_cli pull.
Pluralization is done through special keys. The most common ones are zero , one and other, as shown in the example file above. All plural forms are optional, meaning we can provide as many as we want. While some plural forms might be the same in a given language, they might all differ in another one. To make translating in other languages in the Phrase editor easier, we've decided to always provide the zero form, in addition to one and many in our en.yml file. We enforce this through a static test. That's also why we also have exclude_empty_zero_forms: true so that whenever the zero form is the same as other, we can skip translating it in Phrase and therefore not clutter our fr.yml, de.yml and it.yml files unnecessarily.
Finally, include_empty_translations is required by Rails to work properly, as some translations need to remain explicitly empty, such as the ones that help Rails format numbers.
Keeping Phrase up-to-date
We strive to keep the number of unverified translations as low as possible, because any unverified translation is a translation that is not in production.
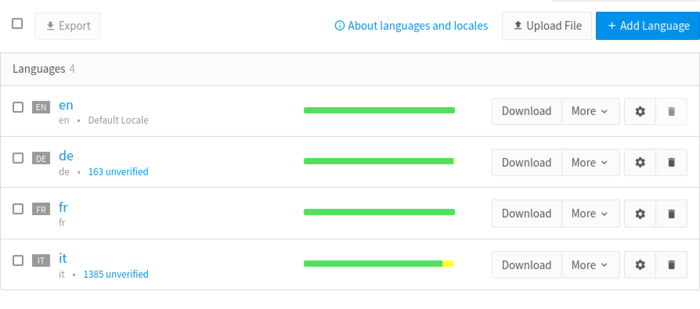
Since we just launched Doctolib in Italy, we have a little less than 10% of our i18n keys not yet available in Italian, as we are slowly catching up. Regarding the 163 unverified German translations, those are for features not used in Germany at the moment. But we’re nonetheless in the process of verifying them, because first of all these features might someday become available in Germany, and also German-speaking developers might want to use the German language while working on French or Italian features.
String interpolation is often a bad idea
While we were doing the switch from French to English, we realized at some point that we had a ton of unused keys in en.yml . Keys from deleted features, keys from refactored code, etc. How to know which keys are actually used?
We first try running grep for every i18n key found in en.yml across the entire codebase. But string interpolation made this impossible.
What's string interpolation? There you go:
if account.doctor?
account_type = 'doctor'
else
account_type = 'patient'
end
# many many lines further down...
I18n.t("common.account.#{account_type}.greetings")
=> Hello, doctor
In this example, it is near impossible to detect through grep that both the keys common.account.doctor.greetings and common.account.patient.greetings are used. What's the solution? This:
if account.doctor?
i18n_key = 'common.account.doctor.greetings'
else
i18n_key = 'common.account.patient.greetings'
end
I18n.t(i18n_key)
To this day, we have not found a way (yet) to prevent string interpolation in i18n keys, but we're working on it. We've however communicated internally largely about it.
The same locale in your test server as in your web server you shall set
When running integration tests with Ruby on Rails, RSpec and Capybara, there are actually two different servers being launched with every test. One is the test server, the one that executes assertions, pilots the browser, opens tabs, etc. And there's the web server, the one that responds to HTTP queries and renders your website.
We've found that both servers do not necessarily answer the same to I18n.locale. For instance, when writing tests for features only available in one country, we'd change the Top-Level Domain (TLD) to .fr, .de. or .it. This would, in turn, change the locale used in our web server through some business logic in our ApplicationController.rb. But the test server would remain in English, regardless of the TLD.
Consequently, trying assert_text I18n.t("some.key") in a test of the French website would be looking for the English translation of some.key, while only the French translation was to be found. Through some fine tuning of our subclasses of ActiveSupport::TestCase, we have managed to sync the locale of both servers.
Preventing the creation of duplicate keys as the Ruby YAML parser silently ignores them and use the latest defined key
Say you have a en.yml file as follows:
en:
greetings:
hello: Hello
bye: Good bye
good_evening: Good evening
bye: Bye
What does I18n.t("greetings.bye") returns? Yep, "Bye". Why? Because the Ruby YAML parser used under the hood silently overwrites any already defined key.
We added a test that is greatly inspired by this StackOverlow answer, to make sure we do not have duplicated i18n keys. The risk was, we could be breaking an untested feature by unknowingly overwriting an existing translation.
it 'makes sure we have no duplicated key' do
yaml_file = File.read('config/locales/en.yml')
assert_empty(PhraseHelper.duplicate_keys(yaml_file))
end
Enforcing a simple format for keys
Although many characters are permitted for keys (only the dot is not, as it marks levels in the hierarchy), we found it much easier to only deal with keys using only basic characters, such as the regular ASCII letters, upper or lower case, digits, hyphens and underscores. Why is that? First of all, because it's more readable, and second of all because it makes grepping through the codebase with regular expressions a lot easier.
it 'enforces a simple format for keys' do
wrongly_formatted_keys =
PhraseHelper
.phrase_keys
.grep_v(%r{^[A-Za-z0-9_-]+(\.[A-Za-z0-9_-]+)*$})
.grep_v(/^i18n\.transliterate\.rule\.[ÄäéöÖßüÜ€]$/) # These keys are special on purpose, exclude them
assert_empty(
wrongly_formatted_keys,
'Please keep translation keys as simple as possible: ' \
'digits, lowercase letters, hyphens and underscores only',
)
end
Preventing the insertion of hidden characters whose behavior might be unexpected
Have you ever seen this warning message on GitHub?

Well, we have. And many times. This happens when people using the Phrase Editor, would mistakenly type special characters on their keyboard while trying to simply type letters with accents.
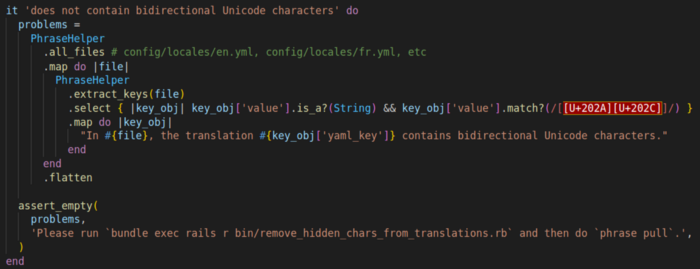
To prevent this from happening again and again, we've added a test. This way, whenever we pull the latest translations from Phrase and open a Pull Request to merge them, we can know right away if something is wrong with any translation.
Here, a screenshot of the test. It's a screenshot as one would not be able to see the hidden Unicode characters otherwise.
Avoid duplicate translations at the same node level
Why create a new translation when one can reuse an existing one? Especially if the translation is a sibling (i.e at the same node level in the YAML file) of the one you're trying to add. Well again, we've added a test so that we avoid duplicating existing English translations. Because we've found that, since the translations YAML files tend to be very big, it is easy to overlook and miss a translation you're looking for, think it does not exist, and add it again.
Ensuring the file is correctly formatted at all times
Because throughout our journey of switching to English as a default locale, we've had to edit our en.yml file many times, we've found that enforcing the formatting makes git diffs easier to review. It's like when one starts using Prettier and stops caring about how to format their JavaScript code. All of a sudden, single quotes, double quotes, escaping characters, where to break a line, etc, are no longer problems.
it 'makes sure en.yml is correctly formatted' do
file = 'config/locales/en.yml'
yaml = YAML.load_file(file)
formatted_yaml = yaml.to_yaml(indentation: 2)
assert_equal(formatted_yaml, File.read(file), <<~MESSAGE.chomp)
The #{file} file is not correctly formatted.
Please put a binding.pry at the end of this test, run it, and launch:
File.write('#{file}', formatted_yaml)
MESSAGE
end
Finding unused keys and removing them
That's the trickiest part. And unfortunately, we don't have a universal answer to that problem. But before finding which keys are not used, how do we even find the ones actually used?
As we've seen before, string interpolation makes it impossible to statically find all used keys. We need to come up with something dynamic.
Logging that a given i18n key is used at runtime is fairly simple, code-wise. "All we have to do" is monkey patch the Ruby gem or the JavaScript package so that we log or store somewhere which keys are being used. For instance, this is most of our JavaScript monkey patch:
import i18n from 'i18n-js'
const addTranslationKey = (key, options) => {
let actualKey = key
if (options?.scope) actualKey = `${options.scope}.${actualKey}`
const set = window._usedI18nKeys || JSON.parse(window.localStorage.getItem('i18n-keys') || '{}')
window._usedI18nKeys = set
if (set[actualKey]) return
set[actualKey] = 1
window.localStorage.setItem('i18n-keys', JSON.stringify(set))
}
i18n._t = i18n.t
i18n.t = function t(key, ...options) {
const translation = this._t(key, ...options)
if (translation) {
const defaultOptionWasUsed = options[0]?.defaults?.length >= 1 && options[0].defaults[0].message === translation
// Do not track if we used a default
if (!defaultOptionWasUsed) addTranslationKey(key, options[0])
}
return translation
}
Regarding our Ruby monkey patch, we've come up with something similar, except that we store the used keys in Redis.
Now that we know how to track the used keys, when do we track them? Two options present themselves:
- We keep a record of the ones used in production
- We keep a record of the ones used in tests (on the CI pipeline for instance)
The second option has the disadvantage of not being a 100% reliable. First, because we don't necessarily have a test for each and every feature of Doctolib, and second because even though we might, not all possible usage scenario for a given feature are tested, therefore we can't be sure that all the i18n keys would actually be used even once.
The first option has the disadvantage of using our users' local storage at their expense and using our production Redis instance for something else that a feature. And likewise, we can't be 100% sure all of our features are even used at all. Also, the keys used today might not be the same ones as tomorrow, because we constantly merge pull requests and rollout new code to production.
Therefore, the idea of capturing a "snapshot" of the keys used at one point in time, without interfering with the production website, sounded like our best bet.
We're now capable of doing that snapshot and computing a diff between our existing keys and the ones used, yet we still have to find a way of making sure we're not deleting keys that could still be used in production, but that are simply not part of a tested feature.
Removing translations as the source language keys are removed
Finally, the last thing we had to deal with was, how do we remove from Phrase (and therefore the other YAML files) the i18n keys that we occasionally remove from en.yml, for instance when we delete a feature?
We came up with a script that runs at night, once a day, on the CI. It basically does a diff of all the i18n keys found in fr.yml, de.yml and it.yml minus those from en.yml. Then, though Phrase's API, it sequentially removes all the French/German/Italian translations for these keys from Phrase. In the next day, when our job than pulls translations from Phrase will run, all our YAML files will contain the same i18n keys.
That's it. This is how Doctolib switched from French as a default language to English. We hope this is helpful. Beyond the migration itself, we've learned a lot and were not only able to improve our translation process but also how features are internationalized, making our engineers' lives easier.
If you want more technical news, follow our journey through our docto-tech-life newsletter.
And if you want to join us in scaling a high traffic website and transforming the healthcare system, we are hiring talented developers to grow our tech and product team in France, Germany and Italy, feel free to have a look at the open positions.